Minule som sa rozpísal o základoch ako je proces. Dnes si vďaka tomu zodpovieme základnú otázku: čo znamená, že aplikácia beží v kontajneri?
Skúsime taký experiment. Spustím si nejaký kontajner, v ktorom bude bežať akože aplikácia. Na simuláciu aplikácie použijem príkaz sleep infinity.
$ docker run --name ubuntu ubuntu:latest sleep infinity
Pozriem sa na bežiace procesy v kontajneri:
$ docker exec -it ubuntu bash
root@fa4b9f3c84f4:/# ps -fax
PID TTY STAT TIME COMMAND
7 pts/0 Ss 0:00 bash
15 pts/0 R+ 0:00 \_ ps -fax
1 ? Ss 0:00 sleep infinity
Zatiaľ tu nie je nič neobvyklé. Moja akože-aplikácia ma PID 1. Pozrime si procesy môjho hosťovského systému. Niekde v tom množstve procesov sa objaví:
$ ps -fax
10550 ? Sl 0:00 /usr/bin/containerd-shim-runc-v2 ...
10570 ? Ss 0:00 \_ sleep infinity
10764 pts/0 Ss+ 0:00 \_ bash
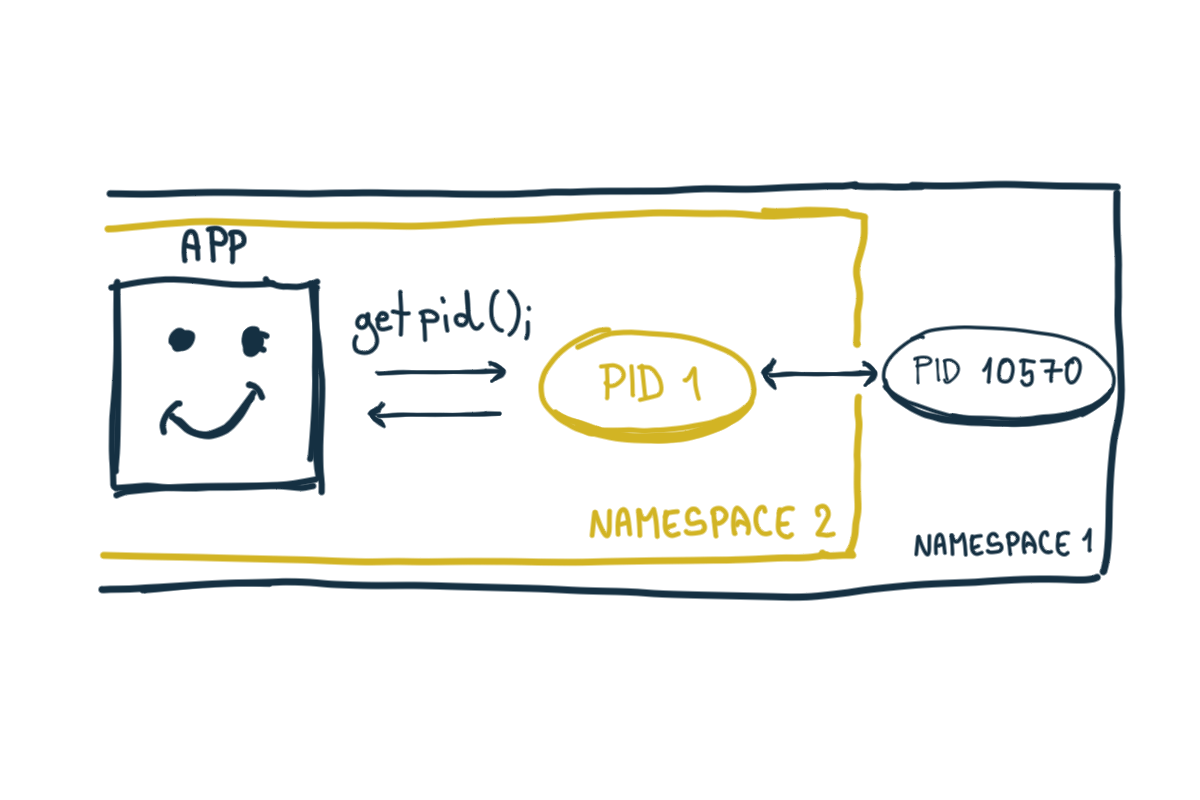
Sú to tie isté procesy, ktoré som videl v kontajneri. Ako je to možné? Moja aplikácia tu má PID 10570 a nie 1. Aj bash je viditeľný s iným PID. Súborový systém tiež nesedí. Vo vnútri kontajnera vidím úplne iný súborový systém ako je na mojom počítači. Ak by šlo o virtualizáciu, proces by patril virtuálnemu stroju. Nie môjmu počítaču. V predchádzajúcom článku som písal, že procesy zdieľajú zdroje ako je súborový systém a iné. Ako teda vytvoriť proces, ktorý si v systéme žije vo svojom izolovanom svete?
Za touto mágiou sa skrýva koncept menných priestorov - namespaces. Ide o funkcionalitu Linuxového jadra, ktorá tak trošku dokáže oklamať proces. Vieme, že aplikácie vždy pristupujú ku zdrojom cez systémové volania. Linux dokáže uzavrieť proces do svojho priestoru, kedy systémové volania budú vracať akúsi ilúziu iného systému. Napríklad volanie getpid tak vráti 1 namiesto správneho 10570.
S mennými priestormi manipulujú systémové volania clone, setns a unshare. Posledné 2 sú dostupné aj ako príkazy terminálu. Menné priestory sú zoradene hierarchicky. Podprocesy teda budú vytvárané v tom istom mennom priestore, v akom je ich hlavný proces.
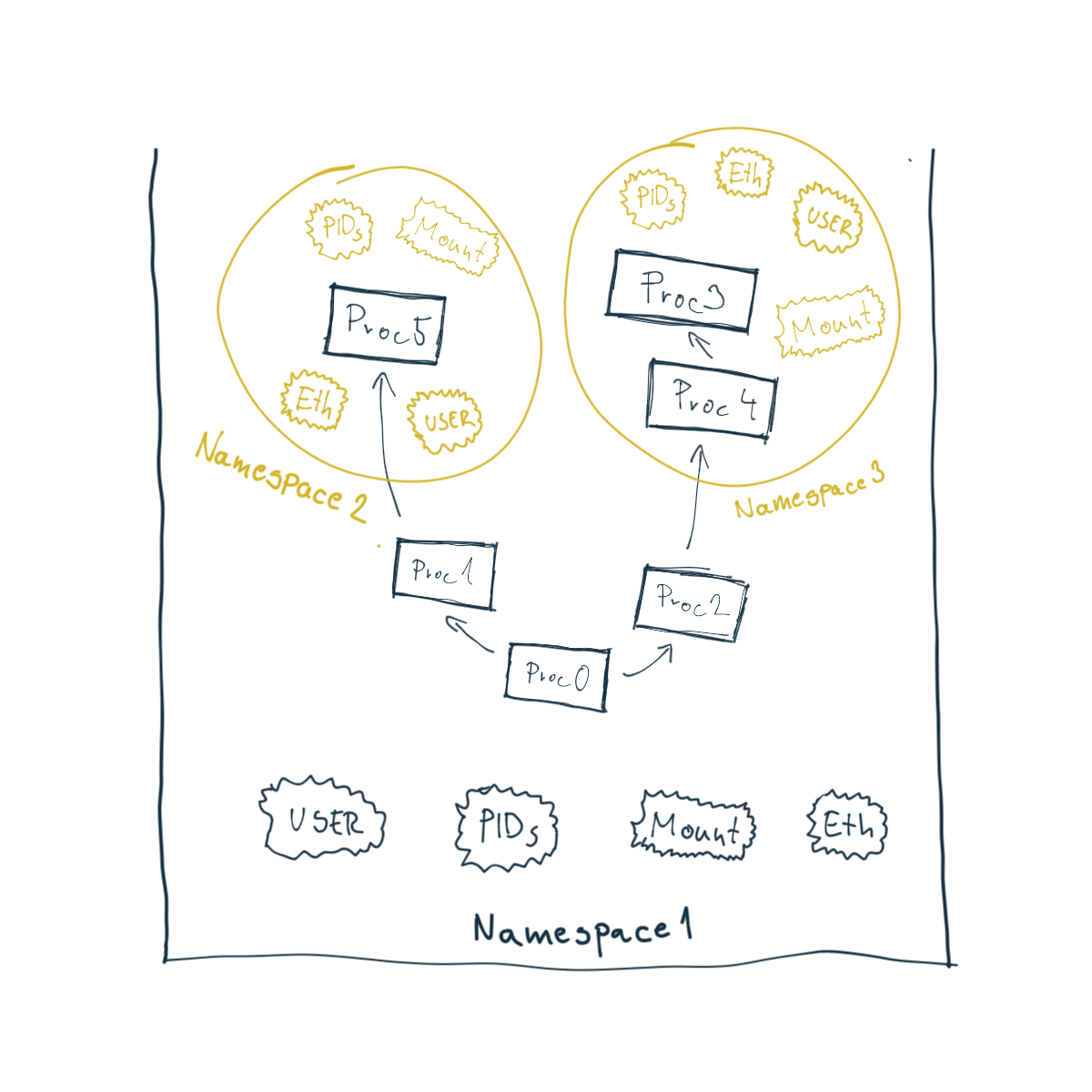
V súčasnosti existuje 8 druhov menných priestorov: UTS, User, PID, Mount, Network, Time, IPC a Cgroup. Už z ich mien je vidieť, aké zdroje izolujú.
Anton - moje behové prostredie
Pre mňa je najlepšie vidieť, ako sa niečo také programuje. Naprogramujem si jednoduché behové prostredie. Budem ho volať Anton. Na ňom si vyskúšam, ako jednotlivé menne priestory fungujú. Základom bude nasledujúci kód:
package main
import(
"os"
"os/exec"
)
func main() {
// zmodifikujem si prompt, aby som vedel rozlíšiť
// či som v hosťovskom systéme alebo v behovom protredí
os.Setenv("PS1", "anton> ")
// pripravim si podproces a presmerujem
// štandardné vstupy a výstupy
cmd := exec.Command(os.Args[1], os.Args[2:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
// sputenie podprocesu
cmd.Run()
}
Tento jednoduchý program nerobí nič iné, len spustí iný program ako jeho podproces. V predchádzajúcom článku som používal syscall.ForkExec() . Tu používam Go variantu cmd.Command(). Táto funkcia mi umožní jednoducho presmerovať štandardné vstupy a výstupy stdin, stoud, strerr. To je z dôvodu, aby som z podprocesom vedel komunikovať. Skompilujem a spustím si Antona s podprocesom /bin/sh.
$ go build -o anton
$ ./anton /bin/sh
anton>
Menný priestor - User
Skúsme sa pozrieť, pod akým používateľom môj podproces beží.
anton> whoami
zdenkov
anton> hostname
MY-DESKTOP
Nič prevratné sa neudialo. Anton a jeho podproces zdieľajú spoločné zdroje ako používateľ, sieťové rozhranie, hostname. Antona upravím teda tak, aby podproces mal svoj vlastný používateľský priestor.
package main
import(
"os"
"os/exec"
"syscall"
)
func main() {
// zmodifikujem si prompt, aby som vedel rozlíšiť
// či som v hosťovskom systéme alebo v behovom protredí
os.Setenv("PS1", "anton> ")
// pripravim si podproces a presmerujem
// štandardné vstupy a výstupy
cmd := exec.Command(os.Args[1], os.Args[2:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
// nový podproces bude mať vlastné menný
// priestor pre použivateľa
cmd.SysProcAttr = &syscall.SysProcAttr {
Cloneflags: syscall.CLONE_NEWUSER,
}
// sputenie podprocesu
cmd.Run()
}
Go mi umožňuje ovplyvniť systémové volanie clone pomocou štruktúry cmd.SysProcAttr .Parametrom Cloneflags zadefinujem príznaky, ktoré hovoria aké nové menné priestory chcem vytvoriť pre podproces. V tomto prípade použijem syscall.CLONE_NEWUSER, ktorý povie jadru Linuxu aby proces používal vlastný používateľský priestor. Malé upozornenie: tento parameter je dostupný len pre Linux platformu a pre Windows neexistuje. Skompilujem Antona a opäť spustím bash ako podproces.
$ go build -o anton
$ ./anton /bin/sh
Pod akým používateľom teraz beží môj podproces?
anton> whoami
nobody
anton> id
uid=65534(nobody) gid=65534(nogroup) groups=65534(nogroup)
Používateľ nobody je trošku divočina, ale nie je to môj zdenkov. Skúsim si v bash podprocese vytvoriť nejaký súbor. Súbor je vytvorený s nobody vlastníkom.
anton> touch helloworld
anton> ls -l
-rw-rw-r-- 1 nobody nogroup 0 helloworld
-rw-rw-r-- 1 nobody nogroup 605 main.go
V rámci môjho behového prostredia to vyzerá v poriadku. Proces však zdieľa môj súborový systém. Aké prístupové práva bude mať tento súbor v hosťovskom systéme? Aké práva Linux skutočne nastavil?
$ ls -l
-rw-rw-r-- 1 zdenkov zdenkov 0 helloworld
-rw-rw-r-- 1 zdenkov zdenkov 605 main.go
Linux na pozadí premapoval nobody na moje UID. V skutočnosti teda podproces beží stále pod mojím používateľom zdenkov.
Ako ale premapovať nobody na niečo zmysluplné? Napríklad root ? V Linuxe je všetko súbor. Pre mapovanie existuje špeciálny súbor /proc/<pid>/uid_map. Stačí poznať PID podprocesu kontajnera a môžeme si mapovanie prezerať a meniť. V Go nepotrebujeme zasahovať priamo do súboru. Je k tomu už pripravená štruktúra syscall.SysProcIDMap. Upravím teda Antona tak, že pridám mapovanie používateľa a skupiny:
package main
import (
"os"
"os/exec"
"syscall"
)
func main() {
// zmodifikujem si prompt, aby som vedel rozlíšiť
// či som v hosťovskom systéme alebo v behovom protredí
os.Setenv("PS1", "anton> ")
// pripravim si podproces a presmerujem
// štandardné vstupy a výstupy
cmd := exec.Command(os.Args[1], os.Args[2:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
// nový podproces bude mať vlastné menný
// priestor pre použivateľa
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUSER,
//mapovanie použivateľa
UidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: os.Getuid(),
Size: 1,
},
},
// mapovanie skupiny
GidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: os.Getuid(),
Size: 1,
},
},
}
// sputenie podprocesu
cmd.Run()
}
Parameter ContainerID určuje UID vo vnútri menného priestoru a HostID určuje skutočné UID. V tomto prípade sa teda moje UID namapuje na UID 0, čo je v Linuxe root. To isté platí aj o skupinách. Skompilujem Antona, spustím opäť bash a poďme sa pozrieť, pod akým užívateľom pobeží môj podproces:
$ go build -o anton
$ ./anton /bin/sh
anton> whoami
root
anton> id
uid=0(root) gid=0(root) groups=65534(nogroup)
Už je to lepšie. Zbavil som sa nogroup a mám root-a. Je to však skutočný root? Vytvorím si súbor, ukončím Antona a pozriem sa, aké práva budú súboru pridelené:
anton> touch helloworld
anton> ls -l
-rw-rw-r-- 1 root root 0 helloworld
-rw-rw-r-- 1 root root 931 main.go
anton> exit
$ ls -l
-rw-rw-r-- 1 zdenkov zdenkov 0 helloworld
-rw-rw-r-- 1 zdenkov zdenkov 931 main.go
Mapovanie teda funguje ako som očakával. Používateľ root je skôr akýsi pseudo-root. Akýkoľvek neprivilegovaný používateľ sa takto vie stať rootom. Toto je veľmi zaujímavý moment. Tento princíp umožňuje beh tzv. “rootless” kontajnerov.
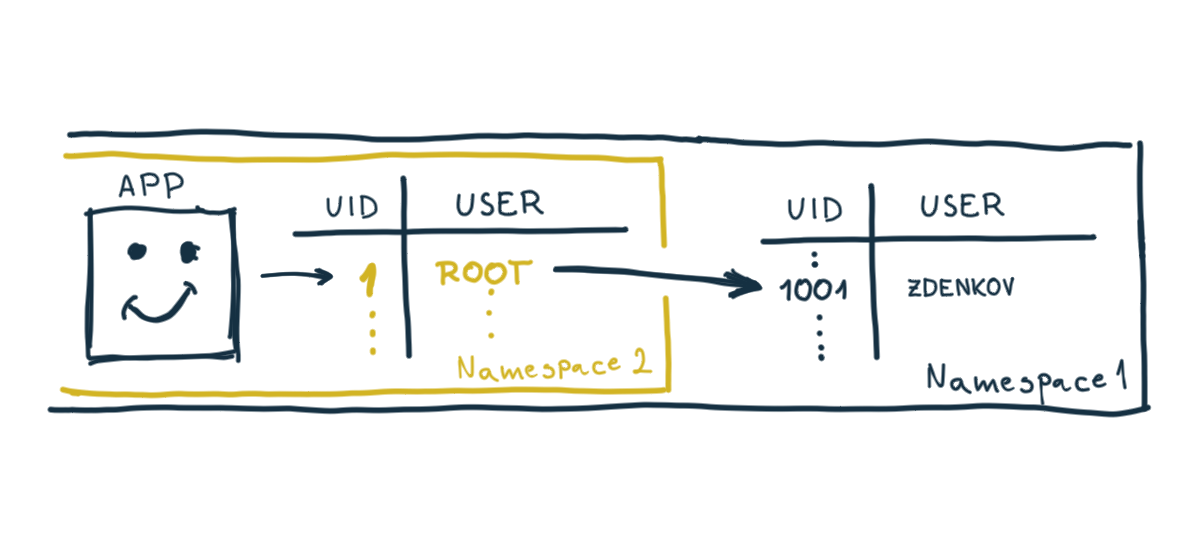
Docker štandardne tento menný priestor nepoužíva. Namiesto toho beží priamo ako root používateľ. To má svoje výhody. Kontajnery tak bežia hladko bez akýchkoľvek reštrikcii. Sú tu ale veľké bezpečnostné riziká. Ak útočník unikne z kontajneru do hosťovského systému, nielenže získava root práva v hosťovskom systéme, ale aj vo všetkých bežiacich kontajneroch. Tomu sa v Dockeri dá zabrániť použitím userns-remap funkcionality.
S používateľským menným priestorom som nezačal náhodou. S mennými priestormi totiž môže manipulovať len root. Jedinou výnimkou je práve používateľský menný priestor. Ten mi umožnil získať potrebné práva, aby som mohol používať ďalšie menné priestory.
Menný priestor - PID
Na plnohodnotné behové prostredie mi používateľský menný priestor nestačí. Skúsim si teraz izolovať procesy. Podprocesu pridám nový PID menný priestor. K tomu súži príznak syscall.CLONE_NEWPID:
// nový podproces bude mať vlastné menný
// priestor pre použivateľa a PID
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUSER | syscall.CLONE_NEWPID,
//mapovanie použivateľa
UidMappings: []syscall.SysProcIDMap{
Antona opäť skompilujem, spustím si bash a pozriem sa na aktuálne PID:
anton> echo $$
1
Môj proces má teraz hodnotu 1. Pomaličky som sa teda dostal k tomu, čo som demonštroval na začiatku. Môj podproces má svoj izolovaný pohľad na procesy. Je to presne to, čo sme si demonštrovali na začiatku so sleep infinity. Tu sa dnes ale zastavíme.
Záver
Už asi začíname chápať rozdielom medzi virtualizáciou a kontajnermi. Kontajner stále beží na tom istom systéme a využíva to isté jadro. Najlepšie to vystihla Liz Rice. Tá poukázala na trochu mylnú terminológiu. Nemali by sme to volať kontajner, ale presnejšie by bolo označenie kontajnerovaný proces. Kontajner je nakoniec Linux proces, ktorý beží na hosťovskom systéme ale s limitovaným pohľadom na zdroje.
Oproti virtualizácii nedochádza žiadnemu k bootovaniu ďalšieho jadra, ani k žiadnej emulácii hardware, k žiadnemu alokovaniu pamäti pre rôzne podporné procesy ako systemd. To je aj dôvod, prečo je štart kontajnerov rýchlejší a kontajnery sú ľahšie oproti virtualizácii.
Prečo som v poslednom príklade nepoužil ps ale echo $$?. Je to zámer. Napriek tomu, že proces má svoj vlastný menný priestor, a PID je 1, ps stále vráti všetky procesy s ich pôvodnými ID. Prečo? Naznačím dôvod - všetko je súbor. Tí, čo sa hrabu v Linuxe dlhšie, už asi tušia :)
Ale o tom si povieme až v ďalšom článku.