V tomto článku si ukážeme netradičnú, ale zaujimavú technológiu - ContainerLab. Ukážeme si, ako v kombinácii s Kind môžeme experimentovať s Kubernetes a sieťami.
Hneď na začiatku musím povedať, že som veľmi vďačný ľuďom okolo Cilium a Isovalent. Práve od ních som obkukal ContainerLab. Kredit za tento článok preto patrí špecialne tvorcom Cilium Labov. Inač vrelo odporúčam.
Pri experimentovaní s kontajnermi a Kubernetesom v infraštruktúrach som vždy narazil na jednu obmedzenie - ako si simulovať kontajnery v nejakej sieťovej topológii? Nevedel som sa jednoducho hrať s BGP, load-balancingom alebo simulovať ako sa Kubernetes cluster bude správať v nejakej topológii. Mať doma home-lab s viacerými strojmi a routermi je pre mňa drahé. Toto obmedzenie mi však vyriešil ContainerLab.
Čo je ContainerLab?
Ide o riešenie z dielne Nokia. Áno, je to tá Nokia. Nie, Nokia nieje mŕtva :) Vstala z popola a dnes sa venuju celkom cool veciam. Jednou z nich je aj SR Linux network OS (NOS). Tím okolo Romana Dodina, ktorý rieši tento NOS potreboval nejaký nástroj, ktorým by vedeli testovať ich SR Linux v rôzných topológiach. Namiesto tradičných virtuáliek ale siahli po kontajneroch. A tak uzrel svetlo sveta ContainerLab. Vďaka otvorenosti sa okolo ContainerLab vytvorila komunita ľudí, ktorí doplnovali ďalšie a ďalšie NOS.
ContainerLab je riešenie, ktoré dokáže simulovať rôzne routre a ich vzájomné prepojenia. A to pomocou kontajnerov a trochu Linuxovej sieťovej magie. Disponuje kontajnerizovanými sieťovými operačnými systémami (NOS), ako sú Cisco (Nexus 9000v, XRd, XRv), Juniper (cRPD/vMX/…), MikroTik RouterOS, Palo Alto PAN, a ďalšie. Na vytvorenie napríklad CLOS topológie teda nepotrebujem kvantum hardvéru. Úplne stačí Docker a dostatok zdrojov na mojom stroji.
Nevýhodou ContainerLabu je, že beží len na Linux stroji. To je spôsobené práve tou Linux sieťovou mágiou. Moje pokusy s ContainerLab na Mac OS s M1/M2 skončili neúspešne. To sa však dá vyriešiť virtualizáciou. Na Macu mi teda nezostalo nič iné, len virtualizovať.
Moja prvá topológia
Teraz, keď už vieme o čo ide, tak si poďme ContainerLab predviesť. Povedzme, že si chcem doma nasimulovať nejaku veľmi jednoduchú, až zbytočnú topológiu. Neskôr do nej budem chcieť osadiť Kubernetes cluster.
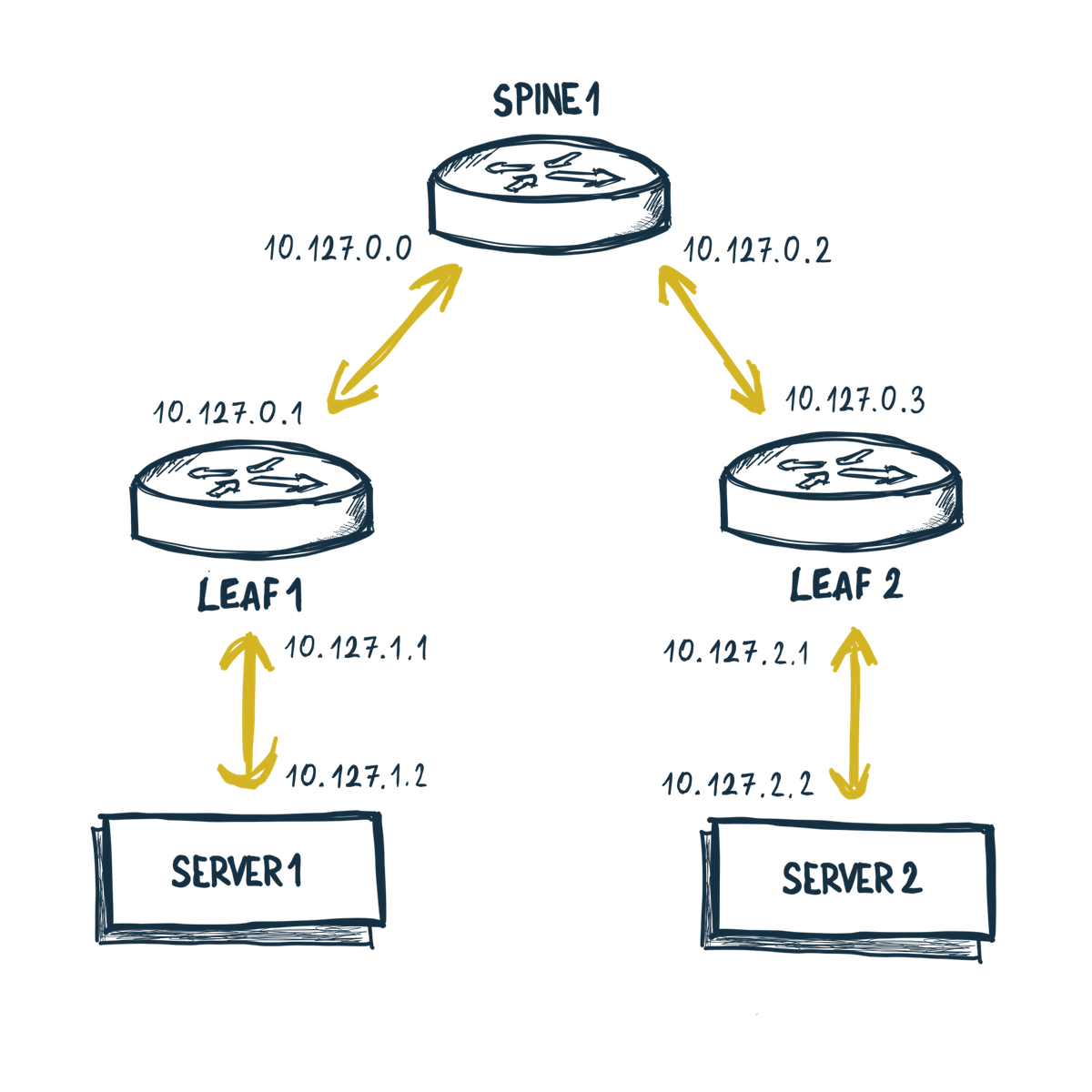
Na vytvorenie mojej topológie budem potrebovať: Linuxový stroj (ideálne amd64), Docker a nainštalovaný samotný ContainerLab. Inštalácia je jednoriadková záležitosť:
$ bash -c "$(curl -sL https://get.containerlab.dev)"
Keďže všetci ľúbime YAML, tak si moju topológiu sieťe nadefinujem ako
homelab.clab.yaml.
name: homelab
mgmt:
network: out-of-band
ipv4-subnet: 172.100.100.0/24
topology:
nodes:
spine1:
kind: linux
image: frrouting/frr:v8.4.1
exec:
- ip addr add 10.127.0.0/31 dev net1
- ip route add 10.127.1.0/24 via 10.127.0.1
- ip addr add 10.127.0.2/31 dev net2
- ip route add 10.127.2.0/24 via 10.127.0.3
- iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
leaf1:
kind: linux
image: frrouting/frr:v8.4.1
exec:
- ip addr add 10.127.0.1/31 dev net1
- ip route replace default via 10.127.0.0
- ip addr add 10.127.1.1/24 dev net2
leaf2:
kind: linux
image: frrouting/frr:v8.4.1
exec:
- ip addr add 10.127.0.3/31 dev net1
- ip route replace default via 10.127.0.2
- ip addr add 10.127.2.1/24 dev net2
server1:
kind: linux
image: ghcr.io/hellt/network-multitool
network-mode: container:homecluster-control-plane
exec:
- ip addr add 10.127.1.2/24 dev net1
- ip route replace default via 10.127.1.1
server2:
kind: linux
image: ghcr.io/hellt/network-multitool
network-mode: container:homecluster-worker
exec:
- ip addr add 10.127.2.2/24 dev net1
- ip route replace default via 10.127.2.1
links:
- endpoints: ["spine1:net1", "leaf1:net1"]
- endpoints: ["spine1:net2", "leaf2:net1"]
- endpoints: ["leaf1:net2", "server1:net1"]
- endpoints: ["leaf2:net2", "server2:net1"]
Viem. Ide o trošku dlhšiu záležitosť, ale netreba sa nechať odradiť. Je to proste YAML.
Ten má svoju jednoduchú štrukturu. Poďme si ho rozobrať. Definícia topológie sa skladá
z dvoch časti - nodes a links.
V časti nodes si definujem jednotlivé sieťové komponenty ako routre, switche
a servre. V mojom prípade ide o trojicu routrov spine1, leaf1 a leaf2.
Mám tu ešte 2 servre server1 a server2.
topology:
nodes:
spine1:
...
leaf1:
...
leaf2:
...
server1:
...
server2:
...
To, o aký typ prvku pôjde, povie dvojica parametrov kind a image.
Parameter kind hovorí o aký typ zariadenia pôjde. Každý typ zariadenia
môže mať svoju špecifickú konfiguráciu. Preto ak chcete používať niektorý
konkrétny NOS, je dobré si prejsť dokumentáciu ContainerLab. Parameter image
je už potom len konkrétny obraz daného NOS.
Ja pre routre nepouživam žiadne špecialitky ako Cisco alebo Juniper. Mne
je blízky práve Linux. Pri iných NOS by som sa strácal. Preto moje sieťové
prvky budú kind: linux.
spine1:
kind: linux
image: frrouting/frr:v8.4.1
exec:
...
Ako základ použivam FRR image frrouting/frr, ktorý je napakovaný podporou
pre BGP, IS-IS atď. Hoci momentálne nič z toho nepoužijem. Možno niekedy v
inom článku.
Samotné nastavenie rozhraní a smerovanie je potrebné definovať dodatočne
pre každý komponent. Tu som si dovolil takýto maličky hnus kvôli jednoduchosti.
Snaď mi to odpustite. Od oka som nastavil statické smerovanie v časti exec.
...
leaf2:
kind: linux
image: frrouting/frr:v8.4.1
exec:
- ip addr add 10.127.0.3/31 dev net1
- ip route replace default via 10.127.0.2
- ip addr add 10.127.2.1/24 dev net2
...
Samozrejme exec môžem použiť na akúkoľvek inicializáciu. Táto sekcia je
však typická len pre kind typu Linux. Iné kind disponujú svojimi špecifickými
nastaveniami. Niektoré disponujú variantami, niektoré zase vlastným konfiguračným
súborom. Opäť poviem, že je potrebné pozrieť dokumentáciu k danému kind.
Presunieme sa na druhú časť konfigurácie - links. Táto časť je jednoduchšia
a hovorí, ako budú jednotlivé sieťové prvky poprepájané. Ľudovo povedané ako
budú skáblované.
links:
- endpoints: ["spine1:net1", "leaf1:net1"]
- endpoints: ["spine1:net2", "leaf2:net1"]
- endpoints: ["leaf1:net2", "server1:net1"]
- endpoints: ["leaf2:net2", "server1:net1"]
Tu sa tiež definuje, aké sieťové rozhrania jednotlivé prvky budú mať. Ako je
možné vidieť, ja som si pre rozhrania zvolil netX konvenciu.
Management (Out of the band) sieť
Je tu ešte jedná časť, ktorú som nezmienil. Ide o mgmt.
mgmt:
network: out-of-band
ipv4-subnet: 172.100.100.0/24
Táto časť sa postará o to, že každý prvok v topológii bude mať ešte jedno
sieťové rozhranie - eth0, ktoré bude zapojene do tzv. out-of-band siete.
Čo je táto sieť zač a načo to slúži?
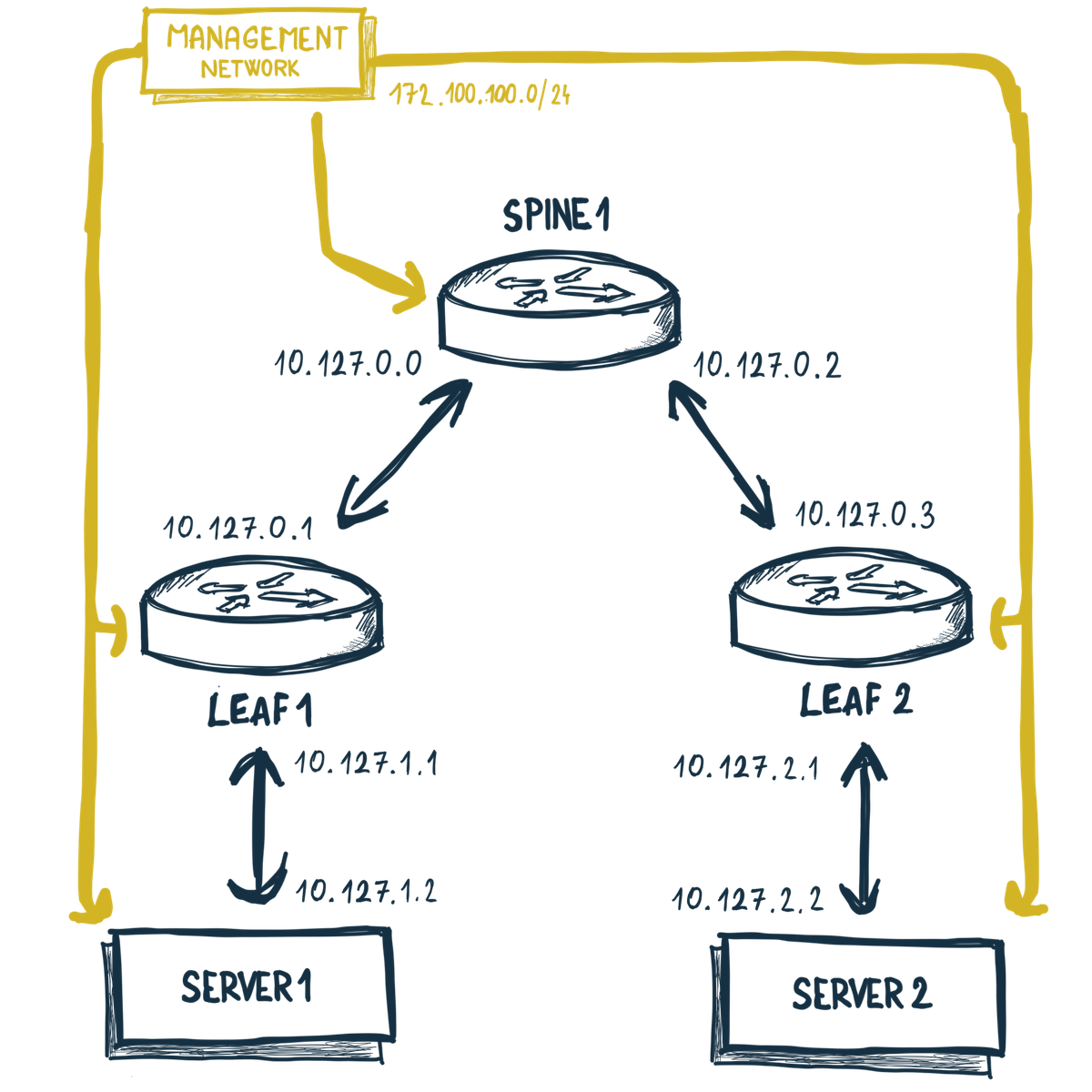
Out-of-band, OOBM, alebo niekde označovaná ako management sieť slúži ako inač -
na riadenie. Skrz tuto sieť pristupuju k prvkom napr. admini, kontrolne systémy alebo
monitoring, realizujú sa rekonfigurácie, reštarty, opravy alebo aj automatizácia.
V mojom prípade pôjde o separátnu docker sieť out-of-band s IP rozsahom
172.100.100.0/24.
Nasadenie topológie
Takže topológiu mam zadefinovanú a môžem pristúpiť k jej nasadeniu. A to príkazom:
$ sudo containerlab deploy --topo homelab.clab.yaml
Na konci by mi aplikácia mala zobraziť tabuľku všetkých komponentov, ktoré boli
nasadené. Taktiež tu môžem vidiet IP adresy komponentov v out-of-band sieti.
+---+----------------------+--------------+---------------------------------+-------+---------+------------------+--------------+
| # | Name | Container ID | Image | Kind | State | IPv4 Address | IPv6 Address |
+---+----------------------+--------------+---------------------------------+-------+---------+------------------+--------------+
| 1 | clab-homelab-leaf1 | 946838322f79 | frrouting/frr:v8.4.1 | linux | running | 172.100.100.3/24 | N/A |
| 2 | clab-homelab-leaf2 | 0056298b1154 | frrouting/frr:v8.4.1 | linux | running | 172.100.100.2/24 | N/A |
| 3 | clab-homelab-server1 | 01f81d6647bd | ghcr.io/hellt/network-multitool | linux | running | 172.100.100.6/24 | N/A |
| 4 | clab-homelab-server2 | 11e5b7b94b44 | ghcr.io/hellt/network-multitool | linux | running | 172.100.100.4/24 | N/A |
| 5 | clab-homelab-spine1 | 3203dd0d5b8b | frrouting/frr:v8.4.1 | linux | running | 172.100.100.5/24 | N/A |
+---+----------------------+--------------+---------------------------------+-------+---------+------------------+--------------+
ContainerLab ešte do /etc/hosts doplní mená komponentov a ich IP adresy.
Čiže ja ku komponentam môžem pristupovať aj priamo cez ssh. V tomto mojom
prípade to však nefunguje, lebo FRR nedisponuje ssh serverom. Pre iné
NOS to ale funguje veľmi pekne.
Skusim teraz overiť, ako bude vyzerať komunikácia medzi server1 a server2.
Skusim teda trasovať komunikáciu:
$ docker exec -it clab-homelab-server1 traceroute 10.172.2.2
traceroute to 10.172.2.2 (10.172.2.2), 30 hops max, 46 byte packets
1 10.127.1.1 (10.127.1.1) 0.024 ms 0.029 ms 0.023 ms
2 10.127.0.0 (10.127.0.0) 0.024 ms 0.029 ms 0.024 ms
3 10.127.0.3 (10.127.0.3) 0.024 ms 0.024 ms 0.022 ms
4 10.127.2.2 (10.127.2.2) 0.018 ms 0.023 ms 0.022 ms
Na výpise môžem vydieť, že komunikácia ide cez leaf1 (10.172.1.1)
na spine1 (10.127.0.0) a potom smerom na leaf2 (10.127.0.3) až na
cieľový server2 (10.172.2.2). Smerovanie paketov funguje správne.
Zdielanie sieťových rozhraní
Pamätáťe si ešte článok o menných priestoroch? Jedným z nich je aj sieťový menný priestor. Každý kontajner má svoj vlastný sieťový menný priestor, v ktorom je vytvorené sieťové rozhranie. Čo ak by ale 2 kontajnery vedeli zdielať sieťový menný priestor? Kontajnery by teda vedeli zdielať sieť, IP adresu atď. Mala odbočka - takto je sieťový menný priestor zdielaný aj v Pode sviacero kontajnermi.
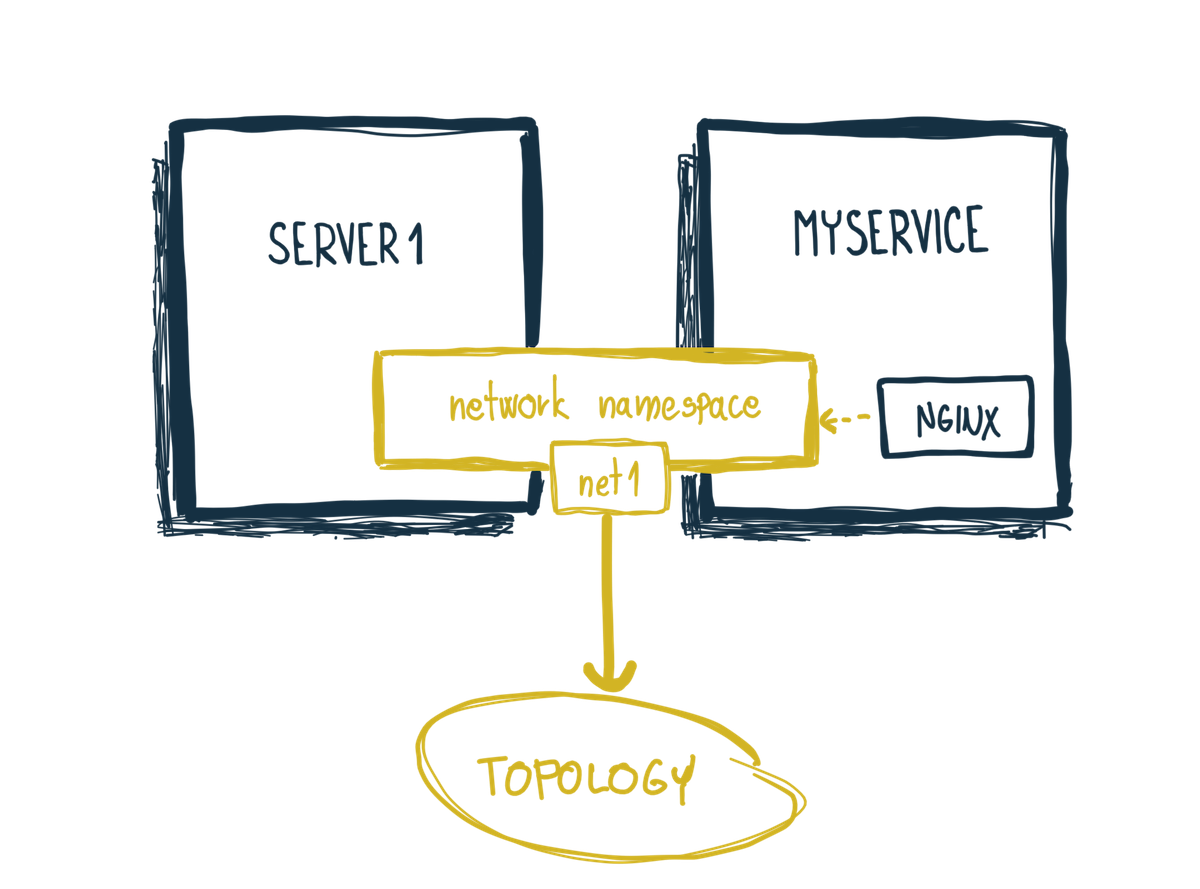
Ale späť k u ContainerLab. Ten disponuje jednou veľmi šikovnou fíčurkou -
Dokáže zdielať sieťové menné priestory. Prvok server1 môže tak
zdielať svoje sieťové rozhranie s ľubovolným Docker kontajnerom.
Výsledkom bude, že tento ľubovolný kontajner sa stane súčasťou sieťovej
topológie. Všetko čo treba, je nastaviť parameter network-mode:
na container:{meno-kontajnera}.
Upravím si konfiguráciu topológie homelab.clab.yaml a pridám
do server1 parameter network-mode: container:myservice
server1:
kind: linux
image: ghcr.io/hellt/network-multitool
network-mode: container:myservice
exec:
- ip addr add 10.127.1.2/24 dev net1
- ip route replace default via 10.127.1.1
Opäť nasadím topológiu, ale teraz s prepínačom --reconfigure:
$ sudo containerlab deploy --reconfigure --topo homelab.clab.yaml
Topológia sa nenaštartuje a ContainerLab bude čakať na myservice kontajner.
Na výstupe sa bude opakovane zobrazovať hláška:
INFO[0044] node "server1" depends on external container "myservice", which is not running yet. Waited 42s. Retrying...
Dôvod je jednoduchý. Kontajner myservice ešte nieje dostupný.
Naštartujem si ho:
$ docker run --name myservice nginx:1.25.2-alpine
Moja topológia sa opäť rozbehne. Ale ako mi v systéme bude bežať myservice?
Konkrétne aké sieťové rozhrania bude mať? Pozriem sa teda na zoznam rozhraní
pomocou ip a:
$ docker exec -it myservice ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
...
68: eth0@if69: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
...
79: net1@if80: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 9500 qdisc noqueue state UP
link/ether aa:c1:ab:8e:18:06 brd ff:ff:ff:ff:ff:ff
inet 10.127.1.2/24 scope global net1
valid_lft forever preferred_lft forever
inet6 fe80::a8c1:abff:fe8e:1806/64 scope link
valid_lft forever preferred_lft forever
Zrazu tam mám aj sieťové rozhranie net1 s IP adresou 10.127.1.2. ContainerLab mi
injektol sieťové rozhranie server1 do kontajnera myservice. Jeho služba by
mala byť takto dostupná aj zo server2:
docker exec -it clab-homelab-server2 curl http://10.127.1.2
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
Do topologie som vďaka tejto vlastnosti zdielania sieťového menného priestoru dokázal priviesť nejakú mojú ľubovolnú službu. Môže to byť MySQL alebo aj celý Kubernetes cluster.
Kind
Predstavíme si teraz iný zaujimavý projekt - Kind. Ide o nástroj na tvorbu lokálnych Kubernetes clustrov. Kind bol vytvorený priamo Kubernetes komunitou a jeho pôvodný účel bol umožniť rýchle e2e testovania počas samotného vývoja Kubernetes.
Kind nepoužíva virtualizáciu. Nody v Kind clustri bežía ako skupina kontajnerov. Vďaka tomu je zmazanie a znovuvytvorenie clustra rychlá záležitosť a je skvelý na tvorbu dočastných clustrov.
Kind je veľmi jednoduchý. Opäť - všetko čo potrebujem, je mať na počítači
nainštalovaný Docker (alebo niečo iné ako Rancher Desktop, Colima atď). Potom
už stači nainštalovať samotný Kind pohodlne napr. cez brew.
brew install kind
Základný cluster viem vytvoriť rýchlo cez terminal pomocou príkazu kind create cluster. Mne
sa ale osvedčil iný spôsob. Rád sa k experimentom vraciam. Často chcem mať clustre reprodukovatelné.
Preto pre svoje experimenty definujem konfiguráciu Kind clustra ako naš milovaný
YAML. Rád sa k experimentom vraciam. Často chcem mať clustre reprodukovatelné.
Vytvorím si teda YAML pre jednoduchý cluster s control plane a jedným workerom. Volajme
ho napr. homecluster.yaml.
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
name: homecluster
nodes:
- role: control-plane
- role: worker
Cluster následne spustím príkazom:
$ kind create cluster --config ./homecluster.yaml
Cluster by mi mal bežať a mal by byť dostupný. Okamžite viem používať kubectl.
Celkom ma zaujima, čo to ten Kind vytvoril.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
homecluster-control-plane Ready control-plane 3m14s v1.27.3
homecluster-worker Ready <none> 2m46s v1.27.3
Vidím, že cluster ma 2 nody. Nejde ale o žiadne virtuálne stroje. Keď sa pozriem čo mi beži v Dockeri, tak uvidím že každý node je reprezentovaný svojim kontajnerom.
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
...
a6cac3d23221 kindest/node:v1.27.3 "/usr/local/bin/entr…" 4 minutes ago Up 4 minutes 127.0.0.1:41665->6443/tcp homecluster-control-plane
e25f6f36fa6d kindest/node:v1.27.3 "/usr/local/bin/entr…" 4 minutes ago Up 4 minutes homecluster-worker
...
Ak potrebujem skontrolovať niečo priamo na node, nepotrebujem ssh, ale stačí
použiť docker exec:
docker exec -it homecluster-control-plane sh
Zostreliť cluster je tiež jednoduchá záležitosť. Stačí použiť:
$ kind delete clusters homecluster
Pre mňa osobne je veľkou výhodou jedoduchosť a rýchlosť ako môžem clustre vytvárať a mazať. Je to operácia, ktorú pri experimentovani robím nepretržite. Pre mňa je jednoduchšie všetko zmazať a vytvoriť cluster nanovo ako opravovať stavy, do ktorých som sa pri experimentovani dostal.
Kind a CNI
Kind používa predvolené CNI kindnet. Zrejme 80% z vás ho nebude mať potrebu
nikdy vymeniť. Plní si svoje základné úlohy. Lenže v momente trochu pokročilejších
nastavení sa začnú vyskytovať problémy. Napríklad ja som natrafil na problém,
keď Kubernetes node mal k dispozícii viacero sieťových rozhraní. Vtedy
kindnet nedokáže vytvoriť interné sieťovanie a úplne zhaluzí routovanie.
Presný dôvod som v čase písania tohto článku ešte nepoznal. Ale mám v pláne
sa na to pozrieť.
Ja teda pre Kind často používam Cilium ako CNI. Nie je to len preto, aby som
eliminoval problémy kindnet. Taktiež chcem mať prostredie, ktoré je
najvernejšie produkcii. Nieje tajomstvo, že Cilium je pre mňa na produkcii
voľba č.1.
Je úplne jedno, či používam Rancher Desktop, Kind alebo Minikube. Stále narážam na tento problém. Tieto predvolené CNI vedia naplniť len základné jednoduché potreby.
Kombinujeme ContainerLab a Kind
Už som tu obkecal ako si viem simulovať sieťovú topológiu a ako si vyrobím Kind cluster. Teraz je čas to spojiť a “osadiť” Kubernetes cluster do topológie.
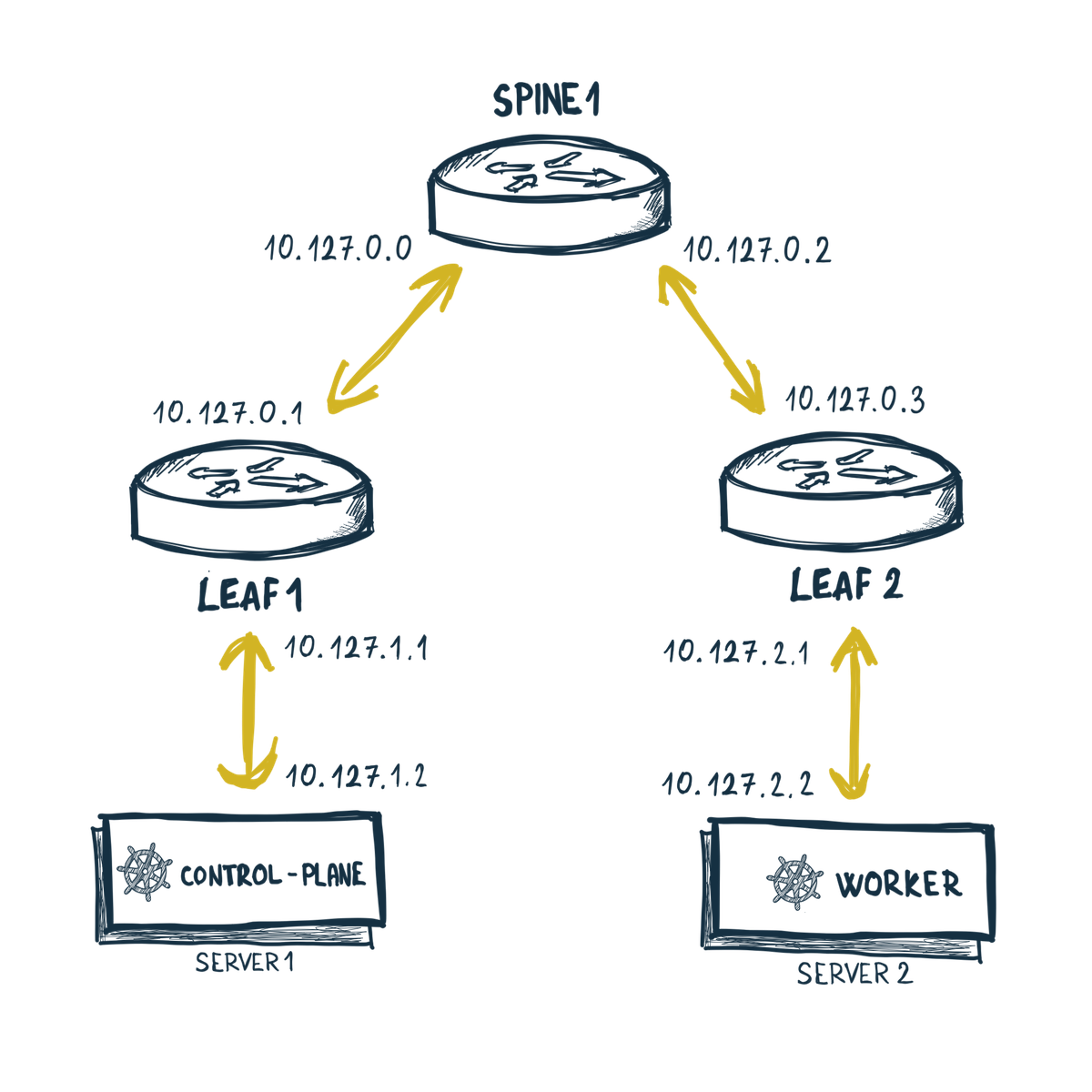
Ak si Pamätáťe, v mojej testovacej topológii mám dvojicu servrov server1 a
server2. Tie sa teraz budú hodiť pre cluster. Vytvorím si Kind cluster s
dvoma nodmi a trošku pokročilejšou konfiguráciou. Môj server1 bude
control-plane a server2 bude worker. Upravím homecluster.yaml:
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
name: homecluster
networking:
serviceSubnet: "100.90.0.0/16"
podSubnet: "100.100.0.0/16"
disableDefaultCNI: true
nodes:
- role: control-plane
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: "10.127.1.2"
- role: worker
kubeadmConfigPatches:
- |
kind: JoinConfiguration
nodeRegistration:
kubeletExtraArgs:
node-ip: "10.127.2.2"
Pribudlo zopár veci. Asi prvé si človek všimne, že som definoval presné IP adresy pomocou node-ip: "...".
Je to z toho dôvodu, že nody budú mať 2 sieťové rozhrania. Čiže ja takto nanútim
clustru aby použival rozhranie z mojej lab siete. Ako som spomínal, kubenet
má problémy s dvoma rozhraniami. Preto som vypol predvolené CNI pomocou disableDefaultCNI: true.
Vytvorim si cluster:
$ kind create cluster --config ./homecluster.yaml
Takýto cluster teraz ešte nebude funkčný a nody budu v stave NotReady.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
homecluster-control-plane NotReady control-plane 16m v1.27.3
homecluster-worker NotReady <none> 16m v1.27.3
Táto nefunkčnosť je momentálne spôsobená tým, že nody zatial majú len jedno
sieťové rozrhanie. Toto rozhranie je v kind sieti a má IP adresu v rozrahu 172.19.0.0/16.
$ docker exec -it homecluster-worker ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
97: eth0@if98: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:13:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.19.0.2/16 brd 172.19.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fc00:f853:ccd:e793::2/64 scope global nodad
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe13:2/64 scope link
valid_lft forever preferred_lft forever
To, ako dostanem tieto nody do mojej topológie už viem - zdielanim sieťových
rozhraní. Upravím si konfiguráciu topológie homelab.clab.yaml. Pridám
pre server1 parameter network-mode: container:homecluster-control-plane
a pre server2 zase parameter network-mode: container:homecluster-worker.
Celý konfigurák bude vyzerať následovne:
name: homelab
mgmt:
network: out-of-band
ipv4-subnet: 172.100.100.0/24
topology:
nodes:
spine1:
kind: linux
image: frrouting/frr:v8.4.1
exec:
- ip addr add 10.127.0.0/31 dev net1
- ip route add 10.127.1.0/24 via 10.127.0.1
- ip addr add 10.127.0.2/31 dev net2
- ip route add 10.127.2.0/24 via 10.127.0.3
- iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
leaf1:
kind: linux
image: frrouting/frr:v8.4.1
exec:
- ip addr add 10.127.0.1/31 dev net1
- ip route replace default via 10.127.0.0
- ip addr add 10.127.1.1/24 dev net2
leaf2:
kind: linux
image: frrouting/frr:v8.4.1
exec:
- ip addr add 10.127.0.3/31 dev net1
- ip route replace default via 10.127.0.2
- ip addr add 10.127.2.1/24 dev net2
server1:
kind: linux
image: ghcr.io/hellt/network-multitool
network-mode: container:homecluster-control-plane
exec:
- ip addr add 10.127.1.2/24 dev net1
- ip route replace default via 10.127.1.1
server2:
kind: linux
image: ghcr.io/hellt/network-multitool
network-mode: container:homecluster-worker
exec:
- ip addr add 10.127.2.2/24 dev net1
- ip route replace default via 10.127.2.1
links:
- endpoints: ["spine1:net1", "leaf1:net1"]
- endpoints: ["spine1:net2", "leaf2:net1"]
- endpoints: ["leaf1:net2", "server1:net1"]
- endpoints: ["leaf2:net2", "server2:net1"]
Teraz nasadim moju topológiu.
$ sudo containerlab deploy --topo homelab.clab.yaml
Keď sa pozriem do kontajnera napr. homecluster-worker, tak tam uvidím nie
jedno eht0, ale dvojicu sieťových rozhraní eth0 a net1:
$ docker exec -it homecluster-worker ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
97: eth0@if98: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:13:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.19.0.2/16 brd 172.19.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fc00:f853:ccd:e793::2/64 scope global nodad
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe13:2/64 scope link
valid_lft forever preferred_lft forever
110: net1@if111: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9500 qdisc noqueue state UP group default
link/ether aa:c1:ab:03:3f:66 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet 10.127.2.2/24 scope global net1
valid_lft forever preferred_lft forever
inet6 fe80::a8c1:abff:fe03:3f66/64 scope link
valid_lft forever preferred_lft forever
Nody však ešte stále niesu spojazdnené a su v stave NotReady. Chyba mi totiž
ešte doinštalovať CNI, keďže predvolené kindnet som vypol kvôli probémom s
viacero sieťovými rozhraniami. Doinštalujem Cilium v minimalistickom nastavení:
$ helm install cilium cilium/cilium --version 1.14.1 \
--namespace kube-system \
--set ipam.mode=kubernetes \
--set tunnel=disabled \
--set ipv4NativeRoutingCIDR="10.127.0.0/16" \
--set k8s.requireIPv4PodCIDR=true
Teraz už len počkať, kedy nabehnú všetky pody. AKeď všetky pody nabehnú, tak
moje nody už budu v stave Ready.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
homecluster-control-plane Ready control-plane 9m50s v1.27.3
homecluster-worker Ready <none> 9m33s v1.27.3
Výsledkom celého tohto snaženia bude, že komunikácia už bude
prebiehať skrz routre leaf1, leaf2 a spine1 a cluster bude vsadený
do topológie. A zabava sa môže začať…
Záver
ContainerLab je technológia, ktora zaujimavým spôsobom využíva kontajnery. Ide o riešenie, ktoré môže byť zaujimavé pre ľudí, čo sa venuju SDN, telekomunikáciam, programujú rôzne inteligentnejšie control-plane a potrebujú jednoducho a lacno overiť funkcionalitu. Dá sa tu hrať s BPG, VXLAN atď. V spojení s Kind je to efektívny spôsob ako sa učiť a experimentovať s Kubernetes multi-cluster prostrediami. Pre mňa osobne je Kubernetes na metalike veľmi zaujímavý.
Ja som napríklad ContainerLab použil na také naivné experimentovanie a overenie si, či Kubernetes API môže byť použité aj na konfiguráciu a riadenie CLOS topológie. Jednotlivé komponenty topológie sa skrz out-of-band sieť pripájali na Kubernetes API.
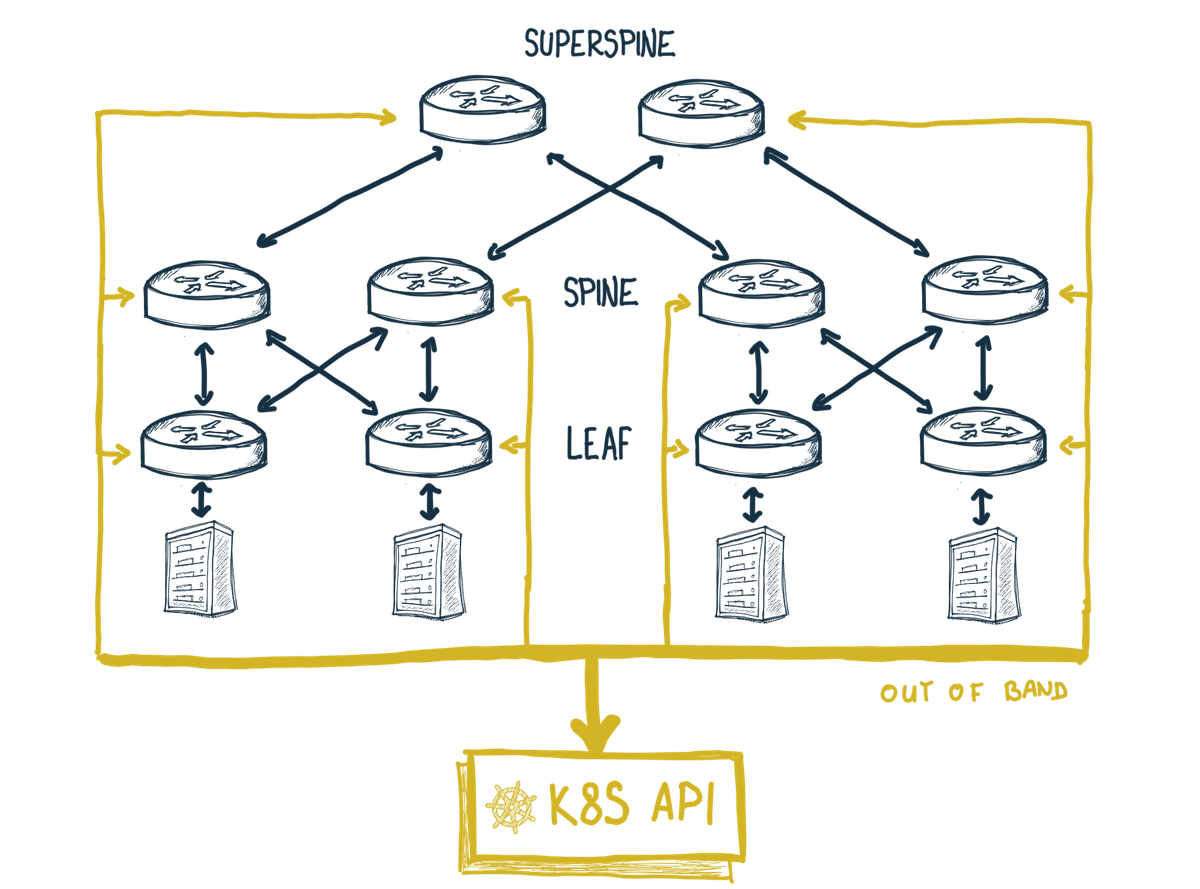
Samozrejme treba povedať aj B - ContainerLab má svoje limity. Stále to nieje a nikdy nebude plnohodnotný lab. Tá fyzická (L1) a linková (L2) vrstva tu proste neexistuje. Napriek tomu si myslím, že ContainerLab je zaujimavý a užitočný počin.